Do you know
本人代码水平拙劣🥲,实现部分仅供参考
南京大学
计算机科学与技术系 计算机系统基础 课程实验 2024
PA1 - 开天辟地的篇章
RTFSC
文件:nemu/src/monitor/sdb/sdb.c
原因:退出时 nemu_state.state 不是 “正常” 的
解决办法:
1 2 3 4 static int cmd_q (char *args) { nemu_state.state = NEMU_QUIT; return -1 ; }
监视点
基本框架
添加 w <expr> 和 d <index> 命令,来添加和删除监视点。
并且需要实现监视点池中链表的维护,监视点表达式的计算。
为了提高 NEMU 的性能,提供监视点功能的开关选项。
链表维护
监视点池中涉及监视点链表和空闲链表,通过 init_wp_pool() 来对其初始化。
1 2 3 4 5 6 7 8 9 10 void init_wp_pool () { int i; for (i = 0 ; i < NR_WP; i ++) { wp_pool[i].NO = i; wp_pool[i].next = (i == NR_WP - 1 ? NULL : &wp_pool[i + 1 ]); } head = NULL ; free_ = wp_pool; }
接着,通过 new_wp() 和 free_wp() 实现监视点的管理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 int new_wp (char * args) { WP *p=NULL ,*q=NULL ; if (free_==NULL ) { printf ("Watchpoints Limit" ); return -1 ; } p=free_; bool success=1 ; p->result = expr(args,&success); if (!success)return -1 ; p->expr = strdup(args); free_=free_->next; if (head!=NULL ) { q=head; while (q->next!=NULL )q=q->next; q->next=p; return 1 ; } head=p; head->next=NULL ; return 1 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 void free_wp (int no) { if (head==NULL ) { printf ("Watchpoint %d not found.\n" ,no); return ; } if (head->NO==no) { WP *wp=head; head=wp->next; wp->next=free_; free_=wp; return ; } WP *p=NULL ; if (head!=NULL ) { p=head; while (1 ){ if (p->next->NO==no){ WP *wp=p->next; p->next=wp->next; wp->next=free_; free_=wp; return ; } if (p->next==NULL ) { printf ("Watchpoint %d not found.\n" ,no); return ; } p=p->next; } } }
监视点求值
为了判断监视点的值是否发生变化,还需要在结构体中添加一个成员来记录。然后通过 check_expr() 来求值和判断变化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 bool check_expr () { bool changed=false ; if (head==NULL )return 0 ; WP *p; bool success=true ; p=head; word_t result = expr(p->expr,&success); if (result!=p->result && success) { printf ("Watchpoint %d changed at 0x%x.\n" ,p->NO,cpu.pc); changed=true ; } if (changed)return 1 ; return 0 ; }
如何阅读手册
程序是个状态机
对于计算 1+2+...+100 的程序的状态机,它是确定性的。
1 (0, x, x) -> (1, 0, x) -> (2, 0, 0) -> (3, 0, 1) -> (4, 1, 1) -> (5, 1, 2) -> (6, 3, 2) -> ... -> (199,4851, 99) -> (200, 4950, 99) -> (201, 4950, 100) -> (202, 5050, 100)
理解基础设施
不必多说,使用过调试器的话肯定有所体会。
RTFM
riscv32 有哪几种指令格式?
There are four core instruction formats.
Register-Type, Immediate-Type, Store-Type, Upper Immediate-Type.
LUI 指令的行为是什么?
LUI (load upper immediate) is used to build 32-bit constants and uses
the U-type format. LUI places the 32-bit U-immediate value into the
destination register rd, filling in the lowest 12 bits with zeros.
LUI
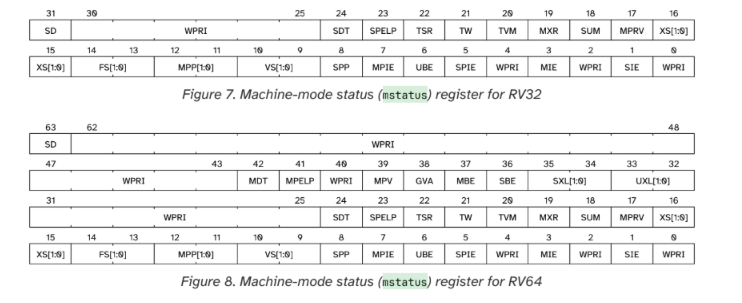
mstatus 寄存器的结构是怎么样的?
The mstatus (Machine Status) register is an MXLEN-bit read/write
register formatted as shown in figures below. It's a Control and
Status Register .
为什么要使用 -Wall 和 -Werror?
At section 3.9, we found that:
-Werror Turn all warnings into errors.
-Wall This enables all the warnings about constructions
that some users consider questionable, and that are easy to avoid (or
modify to prevent the warning), even in conjunction with macros. This
also enables some language-specific warnings.
To add these options, we can leverage compilers to identify potential
issues in our programs.
shell 命令
使用 find . -type f \( -name "*.c" -o -name "*.h" \) -print0 | xargs -0 wc -l 来统计行数
由于我环境经历了多次迁移,似乎把 git 弄坏了(
不过毕竟我没有提交作业的需求,就不注意这些细节了
PA2 - 简单复杂的机器
不停计算的机器
画出在 YEMU 上执行的加法程序的状态机
类似地,使用一个 6 元组来分别表示 PC, R [0], R [1], M [x], M [y], M [z].
1 (0, 0, 0, x, y ,0) -> (1, y, 0, x, y, 0) -> (2, y, y, x, y, 0) -> (3, x, y , x, y, 0) -> (4, x+y, y, x, y, 0) -> (5, x+y, y, x, y, x+y)
RTFSC(2)
立即数背后的故事
1. 假设我们需要将 NEMU 运行在 Motorola
68k 的机器上 (把 NEMU 的源代码编译成 Motorola 68k 的机器码)
此时读取的字节序列会被解释为大端序的,如果在二进制文件中以小端序存储,可能会导致问题。
2. 假设我们需要把 Motorola 68k 作为一个新的 ISA 加入到 NEMU 中
我们需要正确模拟大端序对应的存储结构与解释方式。
立即数背后的故事 (2)
在 RISC-V32 中,一般使用分部加载的方式:
通过 lui 加载高 20 位,addi 加载低 12 位
1 2 lui x10, 0x0D000 addi x10, x10, 0x721
auipc 的执行过程QEMU 内建的第一条指令,正是 auipc
1 0x00000297, // auipc t0,0
在 QEMU 运行过程中,首先调用 exec_once() 来进入相应的处理流程。
1 2 3 4 5 6 7 8 static void exec_once (Decode *s, vaddr_t pc) { s->pc = pc; s->snpc = pc; isa_exec_once(s); cpu.pc = s->dnpc; }
传入的 Decode 是一个包含与 PC 有关变量的结构体
1 2 3 4 5 6 7 typedef struct Decode { vaddr_t pc; vaddr_t snpc; vaddr_t dnpc; ISADecodeInfo isa; IFDEF(CONFIG_ITRACE, char logbuf[128 ]); } Decode;
然后调用 isa_exec_once(s),对于不同的架构,具体的定义不同。
instruction fetch
在 risc-v32 的实现中,代码如下
1 2 3 4 int isa_exec_once (Decode *s) { s->isa.inst = inst_fetch(&s->snpc, 4 ); return decode_exec(s); }
具体的过程又涉及到 vaddr_read() 和 paddr_read(),处理 mmio 地址和 pmem 地址,物理内存上使用 host_read() 读取主机内存上的不同长度字节。
instruction decode
完成取指调用的一系列函数后,isa_exec_once() 会返回 decode_exec(s)
将指令与相应的模式匹配
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 static int decode_exec (Decode *s) { s->dnpc = s->snpc; #define INSTPAT_INST(s) ((s)->isa.inst) #define INSTPAT_MATCH(s, name, type, ... ) { \ int rd = 0; \ word_t src1 = 0, src2 = 0, imm = 0; \ decode_operand(s, &rd, &src1, &src2, &imm, concat(TYPE_, type)); \ __VA_ARGS__ ; \ } INSTPAT_START(); INSTPAT("??????? ????? ????? ??? ????? 00101 11" , auipc , U, R(rd) = s->pc + imm); INSTPAT("??????? ????? ????? 100 ????? 00000 11" , lbu , I, R(rd) = Mr(src1 + imm, 1 )); INSTPAT("??????? ????? ????? 000 ????? 01000 11" , sb , S, Mw(src1 + imm, 1 , src2)); INSTPAT("0000000 00001 00000 000 00000 11100 11" , ebreak , N, NEMUTRAP(s->pc, R(10 ))); INSTPAT("??????? ????? ????? ??? ????? ????? ??" , inv , N, INV(s->pc)); INSTPAT_END(); R(0 ) = 0 ; return 0 ; }
其中,auipc 对应的 (U-Type) 格式如下:
AUIPC
execute
QEMU 在宏中定义了 auipc 的具体行为:
1 INSTPAT("??????? ????? ????? ??? ????? 00101 11" , auipc , U, R(rd) = s->pc + imm);
pattern_decode()中的宏处理了格式字符串:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 static inline void pattern_decode (const char *str, int len, uint64_t *key, uint64_t *mask, uint64_t *shift) { uint64_t __key = 0 , __mask = 0 , __shift = 0 ; #define macro(i) \ if ((i) >= len) goto finish; \ else { \ char c = str[i]; \ if (c != ' ' ) { \ Assert(c == '0' || c == '1' || c == '?' , \ "invalid character '%c' in pattern string" , c); \ __key = (__key << 1) | (c == '1' ? 1 : 0); \ __mask = (__mask << 1) | (c == '?' ? 0 : 1); \ __shift = (c == '?' ? __shift + 1 : 0); \ } \ } #define macro2(i) macro(i); macro((i) + 1) #define macro4(i) macro2(i); macro2((i) + 2) #define macro8(i) macro4(i); macro4((i) + 4) #define macro16(i) macro8(i); macro8((i) + 8) #define macro32(i) macro16(i); macro16((i) + 16) #define macro64(i) macro32(i); macro32((i) + 32) macro64(0 ); panic("pattern too long" ); #undef macro finish: *key = __key >> __shift; *mask = __mask >> __shift; *shift = __shift; }
运行第一个 C 程序
我们需要在此部分实现的指令有 lui, addi,
jal, jalr.
按照 RISC-V 手册实现即可。
需要注意不同指令对待操作数的符号和截断处理。
指令名对照
方法很多,可以根据 opcode 段查询。
程序, 运行时环境与 AM
运行时环境
要求实现 sprintf() 等等库函数,可以参考 glibc 或者 STFW.
RTFSC(3)
对各个 section 的定义如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 ENTRY(_start) PHDRS { text PT_LOAD; data PT_LOAD; } SECTIONS { . = _pmem_start + _entry_offset; .text : { *(entry) *(.text*) } : text etext = .; _etext = .; .rodata : { *(.rodata*) } .data : { *(.data) } : data edata = .; _data = .; .bss : { _bss_start = .; *(.bss*) *(.sbss*) *(.scommon) } _stack_top = ALIGN(0x1000 ); . = _stack_top + 0x8000 ; _stack_pointer = .; end = .; _end = .; _heap_start = ALIGN(0x1000 ); }
阅读 Makefile
Check environment and arguments:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 ifeq ($(findstring $(MAKECMDGOALS) ,clean|clean-all|html) ,)$(info # Building $(NAME) -$(MAKECMDGOALS) [$(ARCH) ]) //... ARCHS = $(basename $(notdir $(shell ls $(AM_HOME) /scripts/*.mk) )) ifeq ($(filter $(ARCHS) , $(ARCH) ) , ) $(error Expected $$ARCH in {$(ARCHS) }, Got "$(ARCH) " ) endif endif
Include AM makefile specified by $(ARCH):
1 -include $(AM_HOME) /scripts/$(ARCH) .mk
in $(ARCH).mk,
it includes nemu.mk, which builds NEMU related driver
and runs NEMU.
it also includes another arch related .mk that overwrites
ARCH_H.
1 2 3 4 5 6 7 8 include $(AM_HOME) /scripts/isa/riscv.mkinclude $(AM_HOME) /scripts/platform/nemu.mkCFLAGS += -DISA_H=\"riscv/riscv.h\" AM_SRCS += riscv/nemu/start.S \ riscv/nemu/cte.c \ riscv/nemu/trap.S \ riscv/nemu/vme.c
Define compilation rule:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 $(DST_DIR) /%.o: %.c @mkdir -p $(dir $@ ) && echo + CC $< @$(CC) -std=gnu11 $(CFLAGS) -c -o $@ $(realpath $< ) $(DST_DIR) /%.o: %.cc @mkdir -p $(dir $@ ) && echo + CXX $< @$(CXX) -std=c++17 $(CXXFLAGS) -c -o $@ $(realpath $< ) $(DST_DIR) /%.o: %.cpp @mkdir -p $(dir $@ ) && echo + CXX $< @$(CXX) -std=c++17 $(CXXFLAGS) -c -o $@ $(realpath $< ) $(DST_DIR) /%.o: %.S @mkdir -p $(dir $@ ) && echo + AS $< @$(AS) $(ASFLAGS) -c -o $@ $(realpath $< ) $(LIBS) : %: @$(MAKE) -s -C $(AM_HOME) /$* archive $(IMAGE) .elf: $(LINKAGE) $(LDSCRIPTS) @echo \ @echo + LD "->" $(IMAGE_REL) .elf ifneq ($(filter $(ARCH) ,native) ,) @$(CXX) -o $@ -Wl,--whole-archive $(LINKAGE) -Wl,-no-whole-archive $(LDFLAGS_CXX) else @$(LD) $(LDFLAGS) -o $@ --start-group $(LINKAGE) --end-group endif $(ARCHIVE) : $(OBJS) @echo + AR "->" $(shell realpath $@ --relative-to .) @$(AR) rcs $@ $^ -include $(addprefix $(DST_DIR) /, $(addsuffix .d, $(basename $(SRCS) ) ))
Build the project in order below
1 2 3 4 5 image: image-dep archive: $(ARCHIVE) image-dep: $(LIBS) $(IMAGE) .elf .NOTPARALLEL: image-dep .PHONY : image image-dep archive run $(LIBS)
1 2 3 4 5 6 7 # Building add-run [riscv64-nemu] # Building am-archive [riscv64-nemu] # Building klib-archive [riscv64-nemu] + CC tests/add.c # Creating image [riscv64-nemu] + LD -> build/add-riscv64-nemu.elf + OBJCOPY -> build/add-riscv64-nemu.bin
实现常用的库函数
stdarg 是如何实现的?
在
参考 GNU/gcc-15.2.0 中 i386 的实现:
计算固定参数的大小
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 words = crtl->args.info.words; n_gpr = crtl->args.info.regno; n_fpr = crtl->args.info.sse_regno; if (cfun->va_list_gpr_size) { type = TREE_TYPE (gpr); t = build2 (MODIFY_EXPR, type, gpr, build_int_cst (type, n_gpr * 8 )); TREE_SIDE_EFFECTS (t) = 1 ; expand_expr (t, const0_rtx, VOIDmode, EXPAND_NORMAL); } if (TARGET_SSE && cfun->va_list_fpr_size) { type = TREE_TYPE (fpr); t = build2 (MODIFY_EXPR, type, fpr, build_int_cst (type, n_fpr * 16 + 8 *X86_64_REGPARM_MAX)); TREE_SIDE_EFFECTS (t) = 1 ; expand_expr (t, const0_rtx, VOIDmode, EXPAND_NORMAL); }
处理栈上的 overflow area, register save area.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 type = TREE_TYPE (ovf); if (cfun->machine->split_stack_varargs_pointer == NULL_RTX) ovf_rtx = crtl->args.internal_arg_pointer; else ovf_rtx = cfun->machine->split_stack_varargs_pointer; t = make_tree (type, ovf_rtx); if (words != 0 ) t = fold_build_pointer_plus_hwi (t, words * UNITS_PER_WORD); t = build2 (MODIFY_EXPR, type, ovf, t); TREE_SIDE_EFFECTS (t) = 1 ; expand_expr (t, const0_rtx, VOIDmode, EXPAND_NORMAL); if (ix86_varargs_gpr_size || ix86_varargs_fpr_size) { type = TREE_TYPE (sav); t = make_tree (type, frame_pointer_rtx); if (!ix86_varargs_gpr_size) t = fold_build_pointer_plus_hwi (t, -8 * X86_64_REGPARM_MAX); t = build2 (MODIFY_EXPR, type, sav, t); TREE_SIDE_EFFECTS (t) = 1 ; expand_expr (t, const0_rtx, VOIDmode, EXPAND_NORMAL); }
基础设施 (2)
指令环形缓冲区 - iringbuf
实现一个环形缓冲区,每次执行指令时写入即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 typedef struct { char buf[10 ][128 ]; int head; int tail; } LogRingbuf; IFDEF(CONFIG_ITRACE, LogRingbuf ringbuf); void ringbuf_push (LogRingbuf *r, const char * log ) { strcpy (r->buf[r->head], log ); r->head = (r->head+1 ) % 10 ; if (r->head == r->tail) r->tail = (r->tail+1 ) % 10 ; } void ringbuf_puts (LogRingbuf *r) { for (int i = r->tail; i!=r->head; i = (i+1 )%10 ) { printf ("%s\n" , r->buf[i]); } }
函数调用的踪迹 - ftrace
偷懒了,并没有完全实现(
先读取传入的 ELF:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <common.h> #include <elf.h> #include <stdio.h> #include <stdlib.h> #include <string.h> void init_ftrace (const char * elf) { Elf64_Ehdr elf_header; FILE *fp = fopen(elf, "rb" ); if (fp == NULL ) { printf ("Failed to open file %s\n" , elf); return ; } size_t count = fread(&elf_header, 1 , sizeof (Elf64_Ehdr), fp); assert(count == sizeof (Elf64_Ehdr)); parse_symbols(fp, &elf_header); }
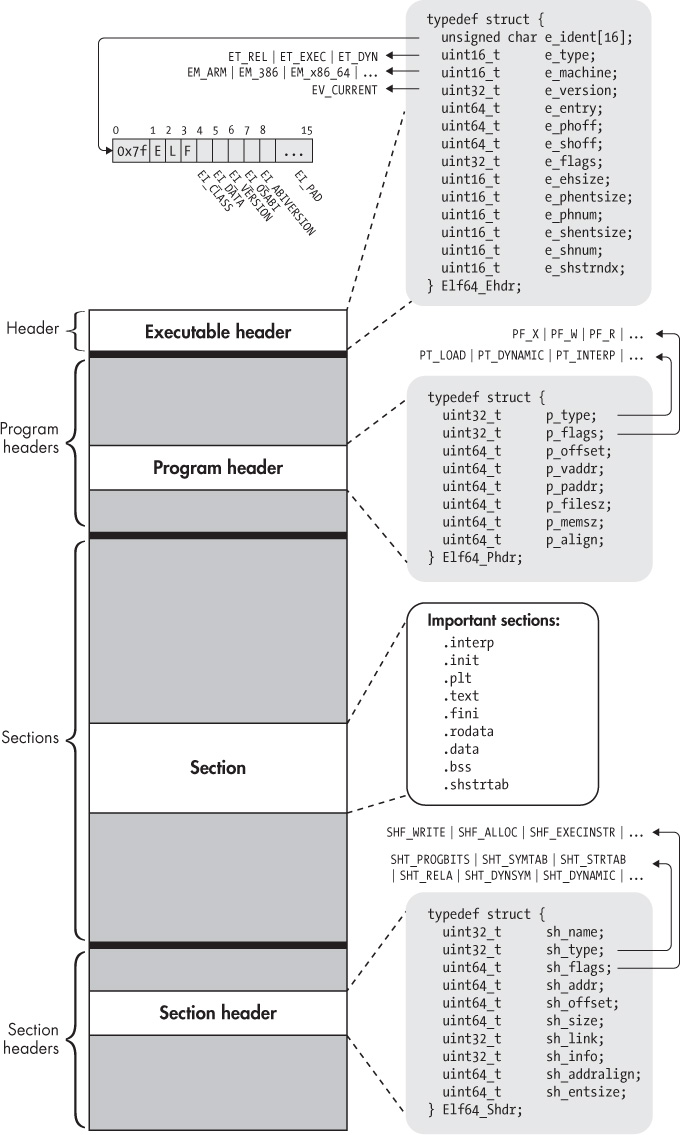
根据 ELF 的结构,我们先读取 Elf64_Ehdr:
ELF
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 ELF header (Ehdr) The ELF header is described by the type Elf32_Ehdr or Elf64_Ehdr: #define EI_NIDENT 16 typedef struct { unsigned char e_ident[EI_NIDENT]; uint16_t e_type; uint16_t e_machine; uint32_t e_version; ElfN_Addr e_entry; ElfN_Off e_phoff; ElfN_Off e_shoff; uint32_t e_flags; uint16_t e_ehsize; uint16_t e_phentsize; uint16_t e_phnum; uint16_t e_shentsize; uint16_t e_shnum; uint16_t e_shstrndx; } ElfN_Ehdr;
解析具体的符号表,并维护一个单向链表:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 void parse_symbols (FILE *fp, Elf64_Ehdr *elf_header) { Elf64_Shdr *sh_table = malloc (elf_header->e_shnum * sizeof (Elf64_Shdr)); fseek(fp, elf_header->e_shoff, SEEK_SET); size_t ret = fread(sh_table, sizeof (Elf64_Shdr), elf_header->e_shnum, fp); assert(ret == elf_header->e_shnum); Elf64_Shdr *symtab_shdr = NULL ; Elf64_Shdr *strtab_shdr = NULL ; for (int i = 0 ; i < elf_header->e_shnum; i++) { if (sh_table[i].sh_type == SHT_SYMTAB) { symtab_shdr = &sh_table[i]; if (symtab_shdr->sh_link < elf_header->e_shnum) { strtab_shdr = &sh_table[symtab_shdr->sh_link]; } break ; } } if (!symtab_shdr || !strtab_shdr) { printf ("Symbol table or string table not found.\n" ); free (sh_table); return ; } Elf64_Sym *sym_table = malloc (symtab_shdr->sh_size); fseek(fp, symtab_shdr->sh_offset, SEEK_SET); ret = fread(sym_table, symtab_shdr->sh_size, 1 , fp); assert(ret == 1 ); char *strtab = malloc (strtab_shdr->sh_size); fseek(fp, strtab_shdr->sh_offset, SEEK_SET); ret = fread(strtab, strtab_shdr->sh_size, 1 , fp); assert(ret == 1 ); int num_symbols = symtab_shdr->sh_size / sizeof (Elf64_Sym); for (int i = 0 ; i < num_symbols; i++) { const char *symbol_name = &strtab[sym_table[i].st_name]; Elf64_Addr symbol_addr = sym_table[i].st_value; unsigned char symbol_type = ELF64_ST_TYPE(sym_table[i].st_info); if (symbol_type == STT_FUNC) { ftrace_append(symbol_name, symbol_addr); } } free (sh_table); free (sym_table); free (strtab); }
Section header 中存放了各个 section 的信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 Section header (Shdr) A file's section header table lets one locate all the file's sections. The section header table is an array of Elf32_Shdr or Elf64_Shdr structures. The ELF header's e_shoff member gives the byte offset from the beginning of the file to the section header table. e_shnum holds the number of entries the section header table contains. e_shentsize holds the size in bytes of each entry. A section header table index is a subscript into this array. Some section header table indices are reserved: the initial entry and the indices between SHN_LORESERVE and SHN_HIRESERVE. The initial entry is used in ELF extensions for e_phnum, e_shnum, and e_shstrndx; in other cases, each field in the initial entry is set to zero. An object file does not have sections for these special indices: SHN_UNDEF This value marks an undefined, missing, irrelevant, or otherwise meaningless section reference. SHN_LORESERVE This value specifies the lower bound of the range of reserved indices. SHN_LOPROC SHN_HIPROC Values greater in the inclusive range [SHN_LOPROC, SHN_HIPROC] are reserved for processor-specific semantics. SHN_ABS This value specifies the absolute value for the corresponding reference. For example, a symbol defined relative to section number SHN_ABS has an ab‐ solute value and is not affected by relocation. SHN_COMMON Symbols defined relative to this section are common symbols, such as FORTRAN COMMON or unallocated C external variables. SHN_HIRESERVE This value specifies the upper bound of the range of reserved indices. The system reserves indices between SHN_LORESERVE and SHN_HIRESERVE, inclu‐ sive. The section header table does not contain entries for the reserved indices.
Elf64_Sym 的定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 String and symbol tables String table sections hold null-terminated character sequences, commonly called strings. The ob‐ ject file uses these strings to represent symbol and section names. One references a string as an index into the string table section. The first byte, which is index zero, is defined to hold a null byte ('\0'). Similarly, a string table's last byte is defined to hold a null byte, ensur‐ ing null termination for all strings. An object file's symbol table holds information needed to locate and relocate a program's sym‐ bolic definitions and references. A symbol table index is a subscript into this array. typedef struct { uint32_t st_name; //This member holds an index into the object file's symbol string table, which holds character representations of the symbol names. If the value is nonzero, it represents a string table index that gives the symbol name. Otherwise, the symbol has no name. unsigned char st_info; unsigned char st_other; uint16_t st_shndx; Elf64_Addr st_value; uint64_t st_size; } Elf64_Sym;
后面遇到 jal 等跳转指令查找这个链表,计算偏移就可以了。
Differential Testing
框架已经实现好了相应的接口,实现一下比较寄存器的值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 bool isa_difftest_checkregs (CPU_state *ref_r, vaddr_t pc) { bool ok = true ; for (int i=0 ;i<32 ;i++) { if (ref_r->gpr[i] != cpu.gpr[i]) { printf ("\n [difftest] inequal reg value in %s: 0x%lx\n" , regs[i], ref_r->gpr[i]); ok = false ; } } if (ref_r->pc != cpu.pc) { printf ("\n [difftest] inequal pc: 0x%lx\n" ,ref_r->pc); ok = false ; } return ok; }
输入输出
实现需要的 IOE 功能都比较简单,这里在跑 microbench 的时候遇到了一个比较怪的问题。
difftest 提示 $PC 不一样,
后面发现是指令实现时对符号的处理出现了问题, 这是很值得注意的.
PA3 - 穿越时空的旅程:
批处理系统
穿越时空的旅程
为了实现异常机制, 我们向状态机引入了如下的新状态:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 typedef struct { word_t gpr[MUXDEF(CONFIG_RVE, 16 , 32 )]; vaddr_t pc; word_t mepc; word_t mcause; word_t priv; word_t mtvec; union { struct { uint32_t UIE : 1 , SIE : 1 , WPRI_0 : 1 , MIE : 1 ; uint32_t UPIE : 1 , SPIE : 1 , WPRI : 1 , MPIE : 1 ; uint32_t SPP : 1 , WPRI_1_2 : 2 , MPP : 2 , FS : 2 ; uint32_t XS : 2 , MPRV : 1 , SUM : 1 , MXR : 1 ; uint32_t TVM : 1 , TW : 1 , TSR : 1 , WPRI_3_10 : 8 , SD : 1 ; } part; word_t val; } mstatus; } MUXDEF(CONFIG_RV64, riscv64_CPU_state, riscv32_CPU_state);
实现异常响应机制
实现异常响应操作:
1 2 3 4 5 6 word_t isa_raise_intr (word_t NO, vaddr_t epc) { cpu.mepc = epc; cpu.mcause = NO; return cpu.mtvec; }
目前所需的异常处理涉及以下的四条指令:csrrw,
csrrs, ecall, mret
1 2 3 4 INSTPAT("??????? ????? ????? 001 ????? 11100 11" , csrrw , I, R(rd) = CSR(imm); CSR(imm) = src1); INSTPAT("??????? ????? ????? 010 ????? 11100 11" , csrrs , I, R(rd) = CSR(imm); CSR(imm) |= src1); INSTPAT("0000000 00000 00000 000 00000 11100 11" , ecall , I, s->dnpc = isa_raise_intr(11 , s->pc)); INSTPAT("0011000 00010 00000 000 00000 11100 11" , mret , I, s->dnpc = cpu.mepc);
CSR 寄存器与序号的对应关系可以在 The RISC-V Instruction Set Manual:
Volume II 找到.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #define CSR(i) *csr_register(i) static vaddr_t *csr_register (word_t imm) { switch (imm) { case 0x341 : return &(cpu.mepc); case 0x342 : return &(cpu.mcause); case 0x300 : return &(cpu.mstatus.val); case 0x305 : return &(cpu.mtvec); default : panic("Unknown csr" ); } }
让 DiffTest 支持异常响应机制
1 2 3 4 5 6 7 8 9 #include <isa.h> word_t isa_raise_intr(word_t NO, vaddr_t epc) { cpu.mepc = epc; cpu.mcause = NO; + cpu.mstatus.val = 0xa00001800; return cpu.mtvec; }
我们需要先在 ref_r 以及 diff_context_t 中引入异常寄存器:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 struct diff_context_t { word_t gpr[MUXDEF (CONFIG_RVE, 16 , 32 )]; word_t pc; word_t mepc; word_t mcause; word_t mtvec; word_t mstatus; }; typedef struct { word_t gpr[MUXDEF (CONFIG_RVE, 16 , 32 )]; vaddr_t pc; word_t mepc; word_t mcause; word_t mtvec; word_t mstatus; } MUXDEF (CONFIG_RV64, riscv64_CPU_state, riscv32_CPU_state);
接着在 difftest.cc 中添加相关支持
1 2 3 4 5 6 7 8 9 10 11 void sim_t::diff_get_regs (void * diff_context) struct diff_context_t * ctx = (struct diff_context_t *)diff_context; for (int i = 0 ; i < NR_GPR; i++) { ctx->gpr[i] = state->XPR[i]; } ctx->pc = state->pc; ctx->mepc = state->mepc->read (); ctx->mcause = state->mcause->read (); ctx->mtvec = state->mtvec->read (); ctx->mstatus = state->mstatus->read (); }
事实上, 由于 NEMU 上的异常机制实现并不完整,
直接使用 DiffTest 和 spike 比较会产生问题.
我们可以选择忽略 mstatus:
1 cpu.mstatus = ref_r->mstatus;
恢复上下文
不过这里需要注意之前自陷指令保存的 PC, 对于 x86 的 int 指令,
保存的是指向其下一条指令的 PC, 这有点像函数调用;
而对于 mips32 的 syscall 和 riscv32 的 ecall,
保存的是自陷指令的 PC, 因此软件需要在适当的地方对保存的 PC 加上 4,
使得将来返回到自陷指令的下一条指令.
啊.. 因为没有对 $pc+4,
导致我一直在调试为什么程序会循环调用自陷操作😢
用户程序和系统调用
加载第一个用户程序
需要理清楚 ELF 文件是怎么被解析和加载的,
然后利用 ramdisk 相关的 api 将其加载到内存中
系统调用
从 navy-apps 的源码中可以知道它是怎么进行 syscall 的,
然后在 nanos-lite 中添加相应的处理. 这里还故意漏掉了一些 GPR 的宏定义,
需要 RTFSC 去补充.
在 Nanos-lite 上运行 Hello
world
听起来只要像 SYS_exit 一样实现 SYS_write 就行了,
但是如果有所疏忽的话, 可能会遇到程序一直打印同一个字符的问题.
一开始我以为是 $pc 相关的操作没做好,
后来查阅资料才发现 printf() 会根据 write() 的返回值做出不同操作: )
hello 程序是什么,
它从而何来, 要到哪里去
虽然这似乎是一道挺重要的必答题,
但是我不太确定自己能否答好.
首先 hello.c 编译好之后会被打包进 ramdisk.img 中,
我们在约定的地址上开始对它进行解析, 而加载的目标地址、栈结构,
这些都已经被提前约定好了, 暂时不需要操作系统去考虑.
printf() 会根据 newlib 中的实现,
从我们实现的 SYS_write 中输出字符.
SYS_write 本身的实现, 回到了 AM 中的 putch 宏.
在 AM 中, 它又变成了最基本的内存操作:
1 2 3 4 5 void putch (char ch) { outb(SERIAL_PORT, ch); } static inline void outb (uintptr_t addr, uint8_t data) { *(volatile uint8_t *)addr = data; }
后续的过程应当在设备实现时就理清楚了吧?(
简易文件系统
这块内容我觉得还挺有意思的, 相关实现都放在 fs.c 中.
框架代码会将 ramdisk 中 (或者说 sfs) 的全部文件元数据在编译时放入一个数组 file_table.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 static Finfo file_table[] __attribute__((used)) = { [FD_STDIN] = {"stdin" , 0 , 0 , invalid_read, invalid_write}, [FD_STDOUT] = {"stdout" , 0 , 0 , invalid_read, invalid_write}, [FD_STDERR] = {"stderr" , 0 , 0 , invalid_read, invalid_write}, #include "files.h" }; {"/share/music/rhythm/Do.ogg" , 6473 , 0 }, {"/share/music/rhythm/Si.ogg" , 6647 , 6473 }, {"/share/music/rhythm/So.ogg" , 6538 , 13120 }, {"/share/music/rhythm/Mi.ogg" , 6611 , 19658 }, {"/share/music/rhythm/La.ogg" , 6542 , 26269 }, {"/share/music/rhythm/Fa.ogg" , 6625 , 32811 }, {"/share/music/rhythm/Re.ogg" , 6503 , 39436 }, {"/share/music/rhythm/empty.ogg" , 4071 , 45939 }, {"/share/music/little-star.ogg" , 140946 , 50010 }, {"/share/files/num" , 5000 , 190956 }, {"/share/pictures/projectn.bmp" , 49290 , 195956 }, {"/share/fonts/Courier-13.bdf" , 25677 , 245246 }, {"/share/fonts/Courier-9.bdf" , 20488 , 270923 }, {"/share/fonts/Courier-11.bdf" , 23272 , 291411 }, {"/share/fonts/Courier-10.bdf" , 21440 , 314683 }, {"/share/fonts/Courier-8.bdf" , 20114 , 336123 }, {"/share/fonts/Courier-7.bdf" , 19567 , 356237 }, {"/share/fonts/Courier-12.bdf" , 24339 , 375804 }, {"/bin/file-test" , 61728 , 400143 }, {"/bin/dummy" , 41536 , 461871 }, {"/bin/time-test" , 45880 , 503407 }, {"/bin/hello" , 46000 , 549287 }, {"总计" , 595287 , 595287 },
一些 makefile 技巧:
1 2 3 4 5 6 7 8 9 RAMDISK = build/ramdisk.img RAMDISK_H = build/ramdisk.h $(RAMDISK) : fsimg $(eval FSIMG_FILES := $(shell find -L ./fsimg -type f) ) @mkdir -p $(@D) @cat $(FSIMG_FILES) > $@ @truncate -s \%512 $@ @echo "// file path, file size, offset in disk" > $(RAMDISK_H) @wc -c $(FSIMG_FILES) | grep -v 'total$$' | sed -e 's+ ./fsimg+ +' | awk -v sum=0 '{print "\x7b\x22" $$2 "\x22\x2c " $$1 "\x2c " sum "\x7d\x2c" ;sum += $$1}' >> $(RAMDISK_H)
虚拟文件系统
对应 5 个文件操作 fs_open, fs_read,
fs_write, fs_lseek, fs_close.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 size_t fs_open (char * pathname, int flags, int mode) { for (int i = 0 ; i < file_cnt; i++) { if (strcmp (pathname, file_table[i].name) == 0 ) { file_table[i].open_offset = 0 ; return i; } } printf ("no such file" ); return -1 ; } size_t fs_read (int fd, void *buf, size_t len) { assert(fd < file_cnt); Finfo *f = &file_table[fd]; size_t real_len = len; if (f->read == NULL && f->open_offset + len > f->size) { real_len = f->size - f->open_offset; } size_t ret; if (f->read) { ret = f->read(buf, f->open_offset, real_len); } else { ret = ramdisk_read(buf, f->disk_offset + f->open_offset, real_len); } f->open_offset += ret; return ret; } size_t fs_write (int fd, const void *buf, size_t len) { assert(fd < file_cnt); Finfo *f = &file_table[fd]; size_t real_len = len; if (f->write == NULL && f->open_offset + len > f->size) { real_len = f->size - f->open_offset; } size_t ret; if (f->write) { ret = f->write(buf, f->open_offset, real_len); } else { ret = ramdisk_write(buf, f->disk_offset + f->open_offset, real_len); } f->open_offset += ret; return ret; } off_t fs_lseek (int fd, off_t offset, int whence) { assert(fd < file_cnt); Finfo *f = &file_table[fd]; int64_t next_offset = f->open_offset; switch (whence) { case SEEK_SET: next_offset = offset; break ; case SEEK_CUR: next_offset += offset; break ; case SEEK_END: next_offset = f->size + offset; break ; default : return -1 ; } if (next_offset < 0 ) next_offset = 0 ; if (next_offset > f->size) next_offset = f->size; f->open_offset = (size_t )next_offset; return f->open_offset; } int fs_close (int fd) {return 0 ;}
操作系统之上的 IOE
实现 gettimeofday
回顾一下之前的时钟实现
1 2 3 4 5 6 7 8 9 10 11 12 size_t gettimeofday (struct timeval *tv, struct timezone *tz) { uint64_t time = io_read(AM_TIMER_UPTIME).us; tv->tv_sec = time / 1000000 ; tv->tv_usec = time % 1000000 ; return 0 ; } case SYS_gettimeofday: { LOG_CALL("SYS_gettimeofday" ); c->GPRx = gettimeofday((struct timeval *)a[1 ], NULL ); break ; }
然后写一个测试程序
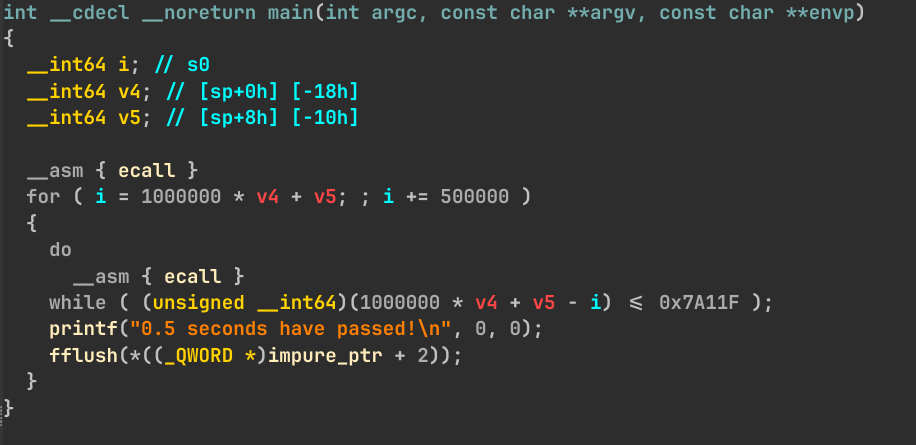
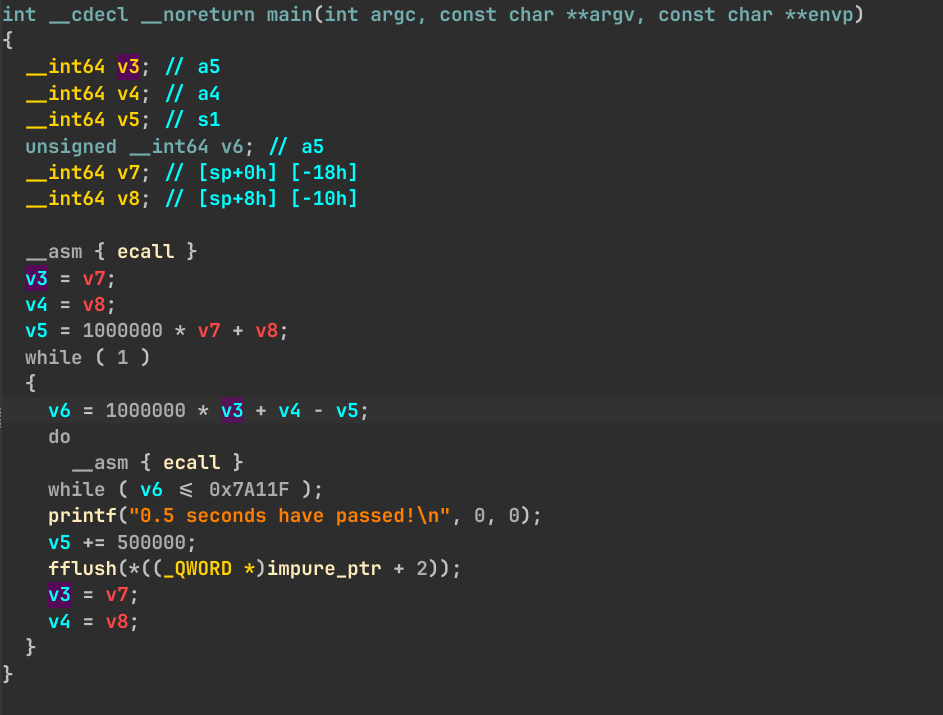
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <stdio.h> #include </home/ubuntu/ics2024/navy-apps/libs/libos/src/syscall.c> #include <sys/time.h> int main () { volatile struct timeval now ; _gettimeofday(&now, NULL ); uint64_t last_us = (uint64_t )now.tv_sec * 1000000 + now.tv_usec; while (1 ) { _gettimeofday(&now, NULL ); uint64_t current_us = (uint64_t )now.tv_sec * 1000000 + now.tv_usec; if (current_us - last_us >= 500000 ) { printf ("0.5 seconds have passed!\n" ); fflush(stdout ); last_us += 500000 ; } } return 0 ; }
volatile 是必须的
With volatile
Without volatile
References
https://lf-riscv.atlassian.net/wiki/spaces/HOME/pages/16154769/RISC-V+Technical+Specifications#ISA-Specifications
https://gcc.gnu.org/onlinedocs/gcc-15.1.0/gcc.pdf
https://elixir.bootlin.com/glibc/glibc-2.42.9000/source
https://gist.github.com/x0nu11byt3/bcb35c3de461e5fb66173071a2379779#file-elf_format_cheatsheet-md