Paper
reading: SLAP: Data Speculation Attacks via Load Address Prediction
on Apple Silicon

https://ieeexplore.ieee.org/document/11023377
Abstract
这篇论文研究了 Apple Silicon 上的 Load Address 预测机制 (LAP).
通过对 LAP 的分析、利用实现了通过侧信道的信息泄漏,绕过 ASLR, 影响控制流,
并且在 Safari 中构造了一个越界读原语.
Speculation and Spectre
现代 CPU 为了提升性能,往往会引入预测执行技术 (Speculative Execution).
例如分支预测 (branch prediction),
其中动态分支预测会基于运行时的动态执行信息,自适应地对分支预测情况做动态调整:
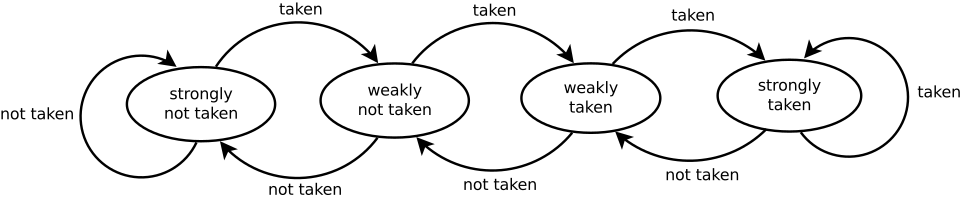 State diagram of 2-bit saturating
counter
State diagram of 2-bit saturating
counter
Spectre 是一个利用预测执行来获取敏感数据的漏洞,它通过侧信道,
获取 CPU 预测执行错误产生的敏感数据.
为了进一步提高 CPU 的性能,
架构师还提出了对数据流的预测来缓解数据冒险 (Data Hazards).
本篇论文主要聚焦于这种现代 CPU 上的数据预测机制以及其安全性的研究.
Background
Cache Organization
on Apple Silicon
Apple CPUs 使用大小核的架构将核心分为 Performance (P)
cores 和 Efficiency (E) cores. 每个核心都有私有的 L1
caches 和同种核心共享的 L2 caches. 这些缓存划分为缓存组,
对于任何一个内存地址,只能存放到由这个地址部分确定的缓存组中.
Side-Channel Attacks on
Caches
由于缓存是共享给所有进程的,
通过测量获得确定数据的延迟可以推测目标进程的秘密活动.
先前的工作可以总结成如下几种方式:
Flush+Reload
\(Flush+Reload\) 是一种基于 Page
Sharing, 针对 Last-Level Cache 的侧信道攻击.
攻击流程分为三个阶段:
- 驱逐目标内存行的缓存
- 等待目标程序去访问
- 重新加载内存行,并测量花费的时间
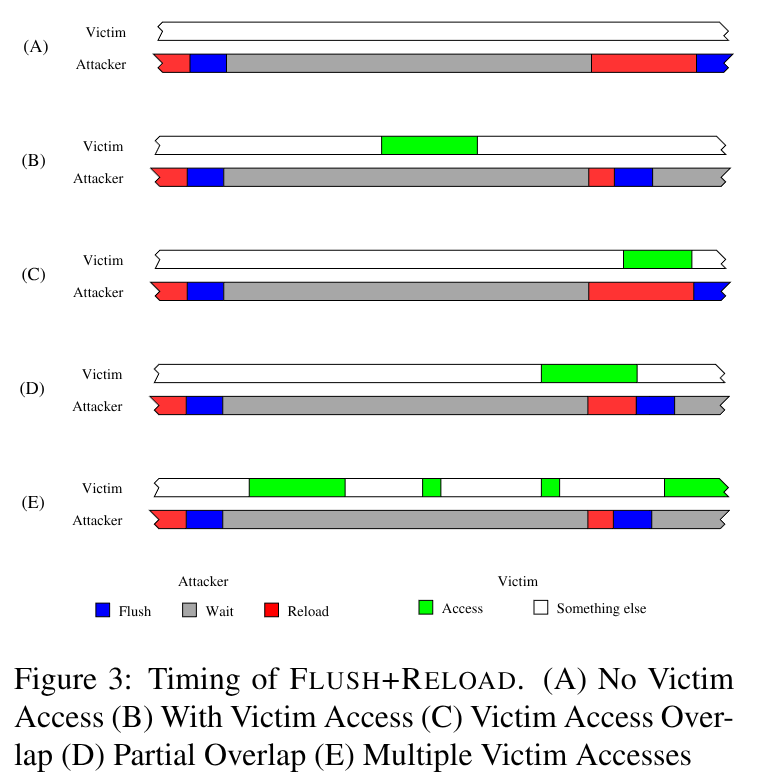
根据时间的长短,我们可以归类为上图的几类情形.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| int probe(void* adrs) {
volatile unsigned long time;
asm __volatile__ (
" mfence \n"
" lfence \n"
" rdtsc \n"
" lfence \n"
" movl %%eax, %%esi \n"
" movl (%1), %%eax \n"
" lfence \n"
" rdtsc \n"
" subl %%esi, %%eax \n"
" clflush 0(%1) \n"
: "=a" (time)
: "c" (adrs)
: "%esi", "%edx" );
return time;
}
|
mfence 和 lfence 确保先前的内存操作都已完成,
防止乱序执行
rdtsc 读取 CPU 时间戳计数器 (TSC) 的值到 EDX:EAX
由于架构差异,在我的 AMD Zen 4
CPU 上似乎无法进行利用.
但是基于类似的思路,我们可以尝试 flush+flush 的攻击:
缓存命中时 clflush 慢:如果一个内存位置(缓存行)当前在
CPU 缓存中 (Hit),处理器执行 clflush
指令来清空它,需要花费额外的时间将该缓存行写回或逐出到更低一级缓存或主内存。
缓存缺失时 clflush 快:
如果一个内存位置不在任何一级缓存中 (Miss),处理器执行
clflush
时,只需要做一次快速的检查和无效化操作,耗时非常短。
我们编写一个共享库 shared_target.c
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| #include <stdio.h>
#include <unistd.h>
#include <string.h>
void target_function(int counter) {
volatile int a = 1;
a = a + counter;
if (counter % 100000 == 0) {
fprintf(stderr, "[Victim] 访问目标函数. 计数: %d\n", counter);
}
}
void *get_target_address() {
return (void *)&target_function;
}
|
一个目标程序 victim.c
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| #include <stdio.h>
#include <stdlib.h>
#include <dlfcn.h>
#include <unistd.h>
typedef void (*TargetFunc)(int);
typedef void* (*GetAddrFunc)();
int main(int argc, char *argv[]) {
void *handle;
TargetFunc target_func;
GetAddrFunc get_addr_func;
handle = dlopen("./libtarget.so", RTLD_LAZY);
if (!handle) {
fprintf(stderr, "错误: 无法加载共享库: %s\n", dlerror());
return 1;
}
target_func = (TargetFunc)dlsym(handle, "target_function");
if (!target_func) {
fprintf(stderr, "错误: 无法找到 target_function: %s\n", dlerror());
dlclose(handle);
return 1;
}
printf("[Victim] target address: %p\n", target_func);
getchar();
int counter = 0;
while (1) {
target_func(counter++);
for (volatile int i = 0; i < 50; i++);
}
dlclose(handle);
return 0;
}
|
然后编写一个 flush+flush 的验证程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
| #include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <time.h>
#include <dlfcn.h>
static inline void flush(void *p) {
asm volatile ("clflush 0(%0)" : : "r" (p) : "memory");
}
static inline uint64_t flush_and_time(void *p) {
uint32_t hi, lo;
uint64_t start, end;
asm volatile ("rdtscp" : "=a"(lo), "=d"(hi));
start = ((uint64_t)hi << 32) | lo;
flush(p);
asm volatile ("rdtscp" : "=a"(lo), "=d"(hi));
end = ((uint64_t)hi << 32) | lo;
asm volatile ("lfence" : : : "memory");
return end - start;
}
#define THRESHOLD 100
#define MEASUREMENT_COUNT 100000
int main() {
uint64_t total_time = 0;
int hit_count = 0;
int miss_count = 0;
void *handle = dlopen("./libtarget.so", RTLD_LAZY);
if (!handle) {
fprintf(stderr, "错误: 无法加载共享库 libtarget.so: %s\n", dlerror());
return 1;
}
void *target_ptr = dlsym(handle, "target_function");
if (!target_ptr) {
fprintf(stderr, "错误: 无法找到 target_function: %s\n", dlerror());
dlclose(handle);
return 1;
}
printf("Address: %p\n", target_ptr);
printf("Threshold (Cycles): %d\n", THRESHOLD);
for (int i = 0; i < 1000; i++) {
flush(target_ptr);
}
for (int i = 0; i < MEASUREMENT_COUNT; i++) {
uint64_t time = flush_and_time(target_ptr);
total_time += time;
if (time > THRESHOLD) {
hit_count++;
} else {
miss_count++;
}
for (volatile int j = 0; j < 50; j++);
}
printf("----------------------------------------\n");
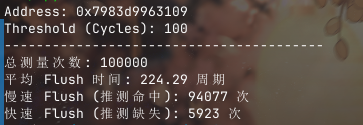
printf("总测量次数: %d\n", MEASUREMENT_COUNT);
printf("平均 Flush 时间: %.2f 周期\n", (double)total_time / MEASUREMENT_COUNT);
printf("慢速 Flush (推测命中): %d 次\n", hit_count);
printf("快速 Flush (推测缺失): %d 次\n", miss_count);
return 0;
}
|
Makefile:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| CC = gcc
CFLAGS = -Wall -Wextra -std=c11
SHARED_FLAGS = -c -fPIC
LINK_SHARED_FLAGS = -shared
LINK_DYNAMIC = -ldl
TARGET_LIB = libtarget.so
TARGET_VICTIM = victim
TARGET_SPY = spy
SHARED_OBJ = shared_target.o
.PHONY: all clean
all: $(TARGET_VICTIM) $(TARGET_SPY)
$(TARGET_LIB): $(SHARED_OBJ)
$(CC) $(LINK_SHARED_FLAGS) $(SHARED_OBJ) -o $@
$(SHARED_OBJ): shared_target.c
$(CC) $(SHARED_FLAGS) $(CFLAGS) $< -o $@
$(TARGET_VICTIM): victim.c $(TARGET_LIB)
$(CC) $< -o $@ $(LINK_DYNAMIC) ./$(TARGET_LIB)
$(TARGET_SPY): main.c $(TARGET_LIB)
$(CC) $< -o $@ $(LINK_DYNAMIC) ./$(TARGET_LIB)
clean:
rm -f $(TARGET_LIB) $(TARGET_VICTIM) $(TARGET_SPY) $(SHARED_OBJ)
|
 A dry run
A dry run

Prime+Probe
相比于可能需要特权才能执行的 \(Flush+Reload\), \(Prime+Probe\) 是一种在非特权下也可行的 Last-Level
Cache 侧信道攻击.
攻击流程也比较类似:
- 攻击者访问一组目标地址,这将填充一个缓存组 (cache
set) 中的多个缓存行
- 等待一段时间
- 攻击者再次访问目标地址,并测量花费的时间
这里还涉及到如何寻找这组目标地址的问题,
这组地址也被称为驱逐集 (eviction set).
不过这又可以单独开个坑去了解了 (
https://arxiv.org/pdf/1810.01497
Control Hazards and
Speculative Execution
这里主要是说预测执行错误导致的 Control Hazards,
产生的缓存数据没有被撤销。导致了可能的侧信道攻击.
Data Hazards and
Out-of-Order Execution
类似地,由于现代 CPU 的乱序执行机制,
有时候会产生当前指令需要使用之前指令的运算结果,
但是结果还没有写回的情形,被称为 Data Hazards.
在下列 Data hazards 的情形中:
Read-After-Write(RAW)
当前指令的源操作数是先前指令的目的操作数
1
2
| ADD X1, X2, X3;
SUBS X4, X1, X5;
|
Write-After-Read(WAR)
寄存器被一条旧的指令读取和新的指令写入
1
2
| LDR X4,[X5];
ADD X5, X6, X7;
|
Write-After-Write(WAW)
寄存器被一条旧的指令写入和新的指令写入
1
2
| ADD X1, X2, X3;
ADD X1, X4, X5;
|
其中,WAR 和 WAW 可以通过寄存器重命名解决 (Register Renaming).
而情形 1 由于必须等待先前指令的完成,只能按顺序执行这些指令.
Load Address Prediction
这种预测是本文主要所研究的,一个 Load Address
Predictor (LAP) 的行为由下图所示.
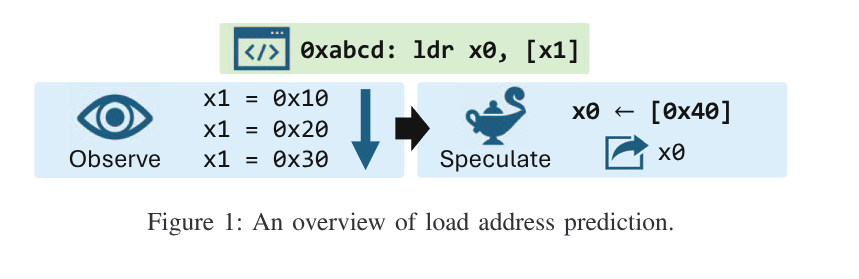
LAPs 一般会记录在 0xabcd 中的地址 x1.
如果这个地址是可预测的,那就会提前加载所预测的地址,
并在指令执行的时候直接转发。如果预测不正确,那么 CPU 会冲刷流水线 (Pipeline
Flush) 并且从正确的加载地址处继续执行.
Reverse Engineering the LAP
在这节中,论文中介绍了如何确认 LAP 在 Apple
Silicon 的存在以及具体机制.

使用以下的 array, 并且测量指令的执行时间:
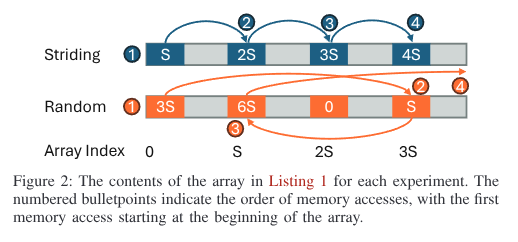
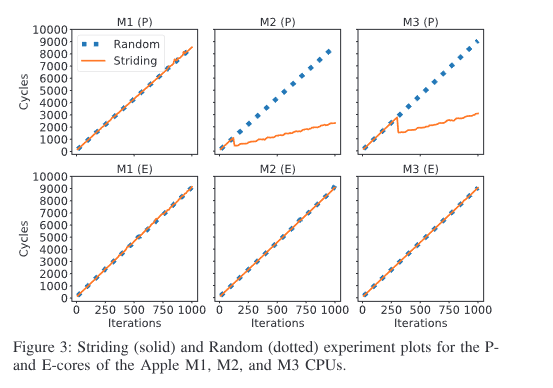
可看出在 M2 (P), M3 (P) 中的加载时间变小了.
接下来,引入了一种实验方法 SA+RV (Striding Addresses from Random
Values), 来确定这是 LAP
内存布局如下:
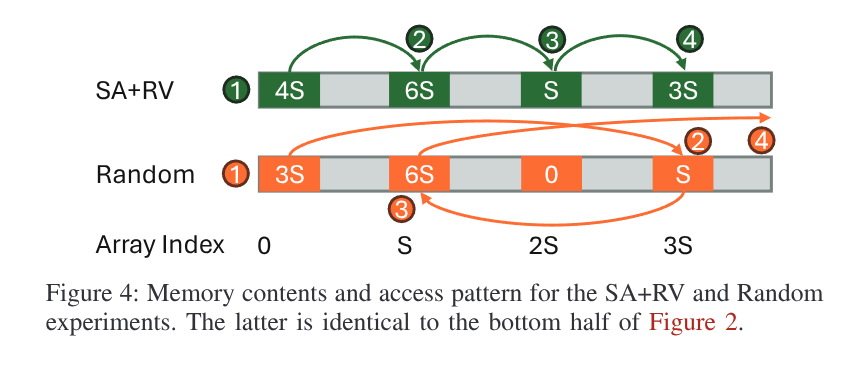
并且修改了遍历逻辑:

这样,array 中的值是随机的,而加载地址仍是可预测的.
在 M2 (P) 和 M3 (P) 上测试发现 LAP 存在:
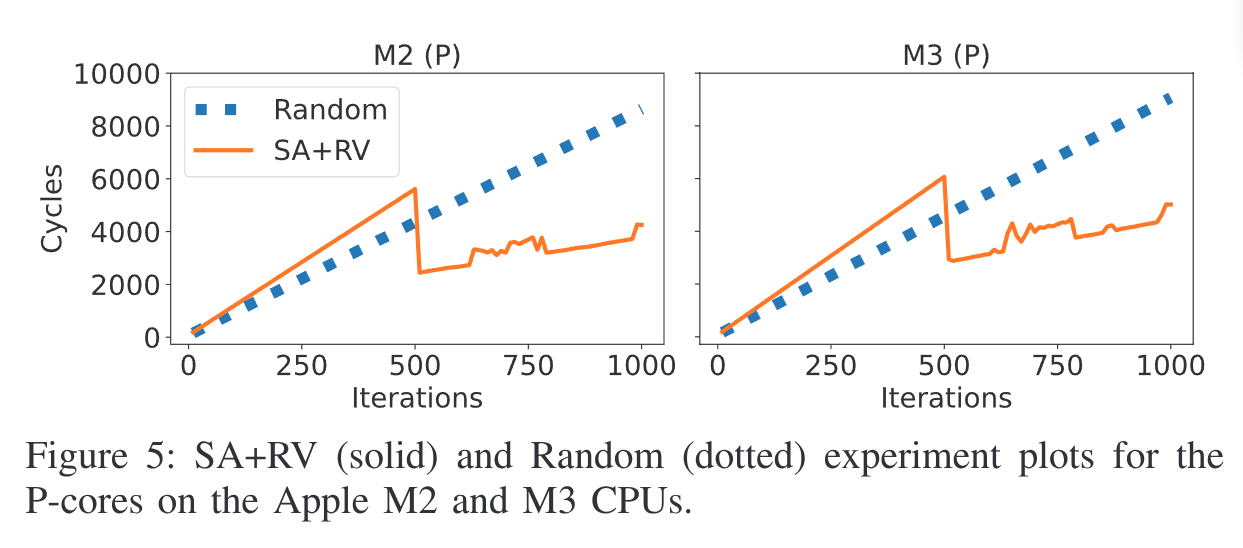
为了进一步探究 LAP 的机制,先前的测试过程中都是预测一直正确的情况,
通过另一种设计,来让预测发生错误.
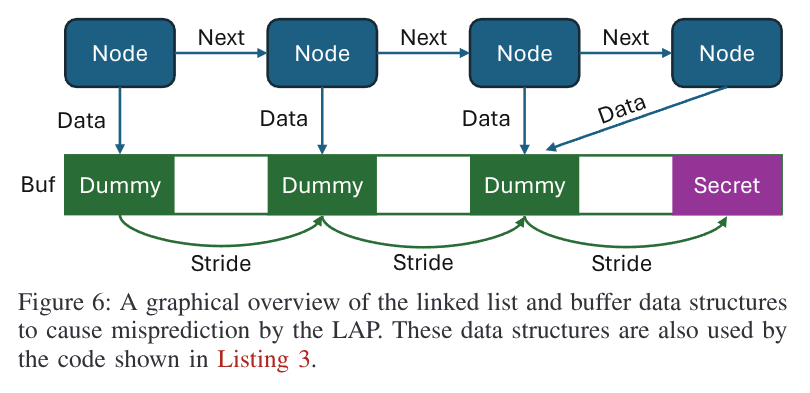
使用之前所提到的 Flush+Reload,
可以判断出 CPU 是否访问了 Secret.

基于上面 Figure 5 的结果,实验使用了 501 个 nodes 的链表,500 个 striding
data pointer. 并且给出了下列的访问延迟图表:

可见 CPU 访问了 Secret.
Spatial Conditions for
Speculation
通过设置不同的测试条件,可以测量 LAP 的具体工作条件.
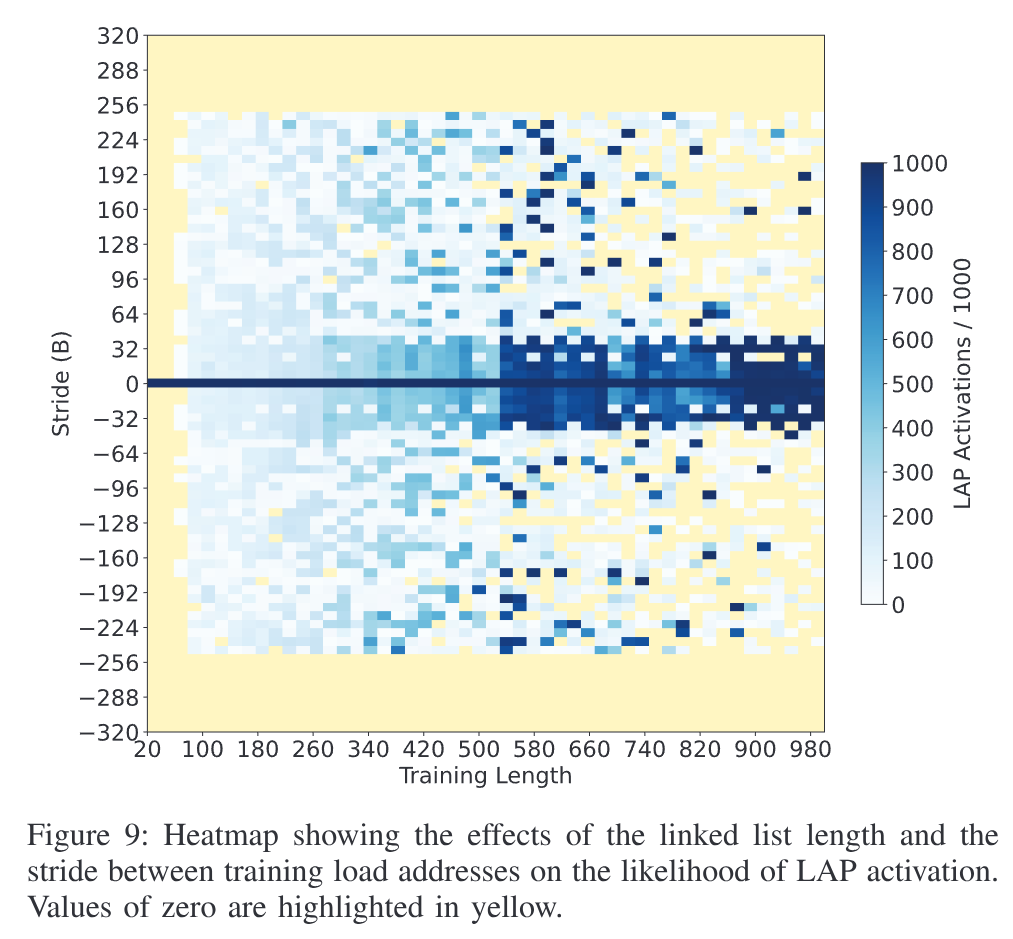
Temporal Conditions for
Speculation
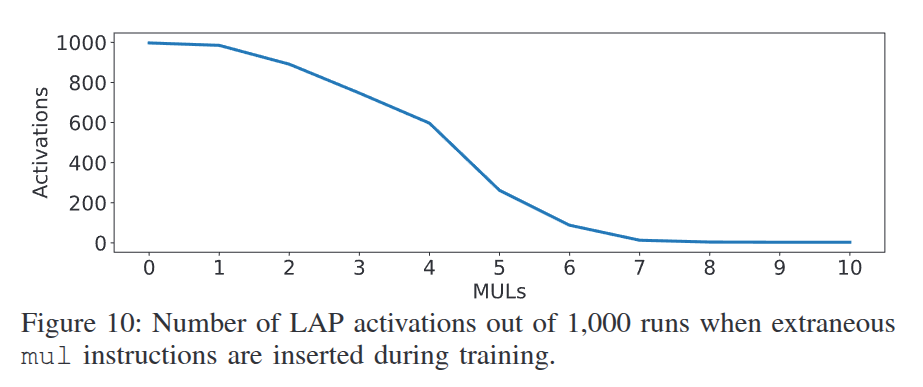
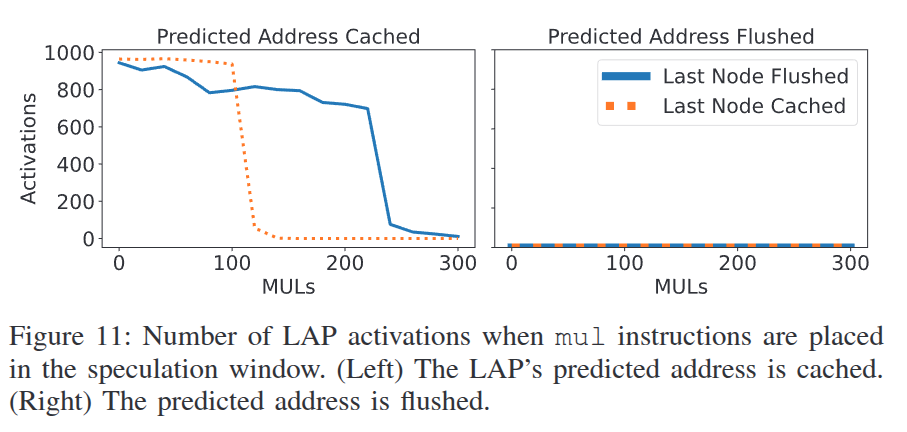
在 Listing 3 的基础上进行修改,
增加一些空转指令来测量侧信道的时间窗口

论文分别测量了在 Line 3 和 Line 7 插入 mul 的结果:
Weaponizing the LAP for
Attacks
这里介绍了两种基于 LAP 的攻击方法
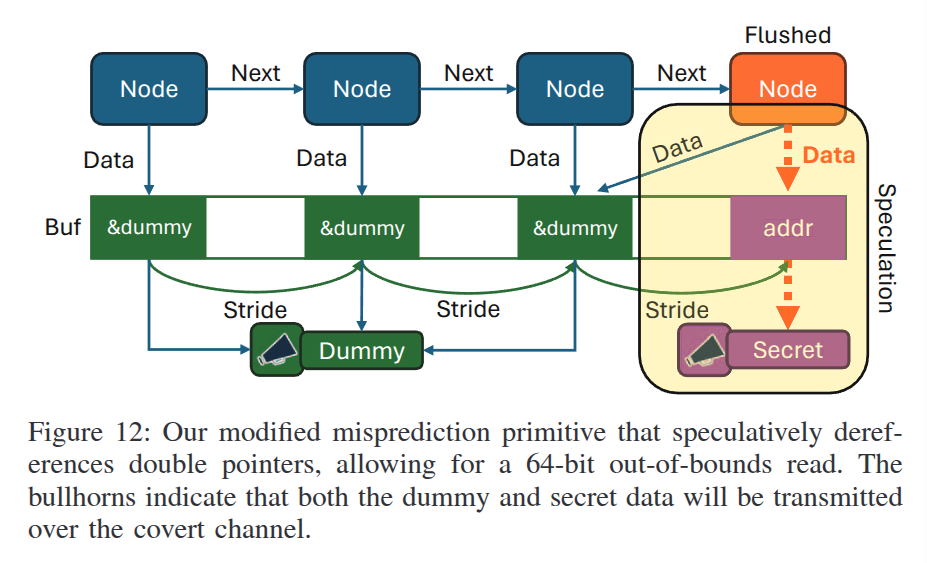
Spectre-LAP
回顾之前访问 Secret 的方法,使用如下的结构和代码,
造成了一个 8 字节的越界读.

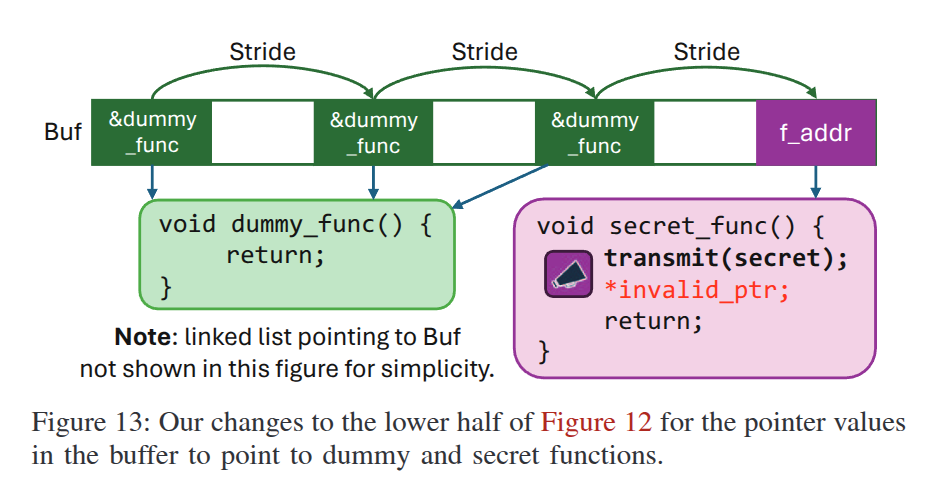
Hijacking Control Flow
用调用函数替代数据的访问,来测试 LAP 是否会同样进行预测

Breaking ASLR on macOS
在 macOS 的内核 XNU 中,其二进制入口点会在一个固定的区间上,
并且在头部存在一个 magic bytes:0xfeedfacf.
在不同的页上搜寻这串魔数,就能绕过 ASLR.
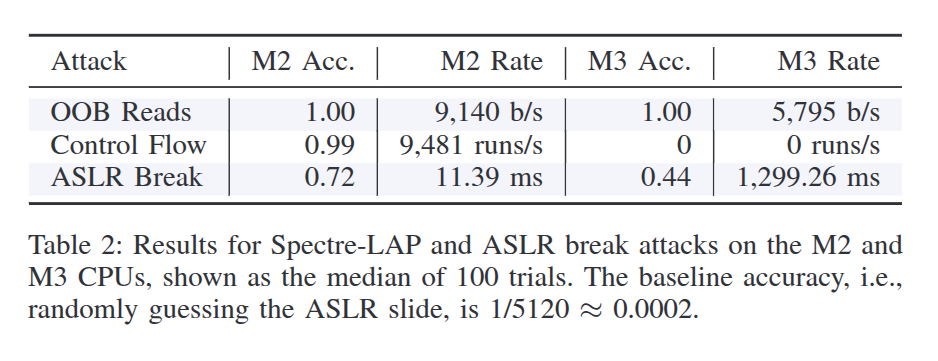
下表是论文中对三种攻击的成功率统计
References
- https://zhuanlan.zhihu.com/p/561643046
- https://en.wikipedia.org/wiki/Branch_predictor
- FLUSH+RELOAD: a high
resolution, low noise, L3 cache side-channel attack
- https://mstmoonshine.github.io/p/flush-reload/